
Node.js中的一些模块
# 什么是Node.js ?
Node.js 不是一门新的编程语言, 也不是一个用于实现具体功能的第三方工具库, 而是一个基于Chrome V8引擎的 JavaScript 运行环境 , 用来支持 JavaScript 代码的执行。用编程术语来讲,Node.js 是一个 JavaScript 运行时(Runtime)。它让 JavaScript 脱离了浏览器环境,可以直接在计算机上运行,极大地拓展了 JavaScript 用途。
记录 Node.js 中的一些内置模块...
# 一、Buffer模块
Buffer ( 缓冲区 )是一个类似于数组的对象 ,用于表示固定长度的字节序列 ;Buffer本质是一段内存空间, 专门 用来存放二进制数据
Buffer实例的创建和字符串转换:
//Node.js 中创建 Buffer 的方式主要如下三种:
// Buffer.alloc()
let buff = Buffer.alloc(5) //创建一个大小为 5 个字节的缓冲区,相当于申请了 5 字节的内存空间,每个字节的值为 0
console.log(buff); // <Buffer 00 00 00 00 00>
// Buffer.allocUnsafe()
let buff2 = Buffer.allocUnsafe(5)
console.log(buff2); //<Buffer 00 00 00 00 00>
// Buffer.from() 可以将一个字符串或数组转为Buffer
let buffer3 = Buffer.from("hello world")
let buffer4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117])
console.log(buffer3); // <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
console.log(buffer4); // <Buffer 69 6c 6f 76 65 79 6f 75>
// Buffer与字符串转换
let str = buffer3.toString()
console.log(str); // hello world
//可以直接通过 [] 下标的方式对Buffer的读取和修改
console.log(buffer3[0]); //104
buffer3[0] = 100
console.log(buffer3[0]); // 100
console.log(buffer3.toString()); //dello world
# 二、fs 文件系统模块
fs 全称为 file system ,称之为 文件系统 ,是 Node.js 中的 内置模块。fs模块可以实现与硬盘的交互,例如文件的创建、删除、重命名、移动,以及文件内容的写入和读取,以及文件夹相关的操作。
# 2.1 文件写入
使用场景 :下载文件、安装软件、保存程序日志(如 Git)、编辑器保存文件、视频录制等需要持久化保存数据的时候,应该想到文件写入
- writeFile 异步写入
- writeFileSync 同步写入
- appendFile / appendFileSync 追加写入
- createWriteStream 流式写入
# 2.1.1 异步写入
语法: fs.writeFile( file,data,[,options ],callback )
- file 写入的路径 ( 文件不存在会自动创建 )
- data 要写入的数据
- options 选项设置(可选)
- callback 回调函数
例如需求 : 在当前 js 文件的同级目录新建一个 " 滕王阁序.txt "文件, 并在txt文件中写入内容 " 时维九月 "
// 1.想要使用 fs 模块需要先使用全局方法require( )导入 fs模块
const fs = require("fs")
// 2 异步的去做磁盘的文件写入,即 fs.writeFile( )是异步的
fs.writeFile("./滕王阁序.txt","时维九月",err=>{
//写入成功时 形参err为null; 写入失败时 err为错误信息对象
if(err){
console.log("写入失败");
return
}
console.log("写入成功");
})
console.log(111)
//先打印111,再打印异步的回调函数里的 "写入成功"或" 写入失败"
# 2.1.2 同步写入
语法: fs.writeFileSync( file, data ,[,options ] ),无回调函数
//同步的去做磁盘的文件写入,即 fs.writeFileSync( )是同步的
fs.writeFileSync("./滕王阁序.txt",",序属三秋")
# 2.1.3 追加写入(异步)
追加写入就是将写入内容追加至文件的末尾,语法与异步写入fs.writeFile( )相同
fs.appendFile("./滕王阁序.txt",",潦水尽而寒潭清",err=>{
if(err){
console.log("追加内容失败");
return
}
console.log("追加内容成功");
})
console.log(11);
//注: 使用异步写入 fs.writeFile( ) 的配置项 { flag:"a" }也可以实现 追加写入的效果 ( 若无此配置项会清空文件内容后再写入内容 )
fs.writeFile("./滕王阁序.txt",",俨骖騑于上路",{ flag:"a" }, err=>{
if(err){
console.log("追加内容失败");
return
}
console.log("追加内容成功");
})
# 2.1.4 同步追加写入
语法:与同步写入fs.writeFileSync( )相同
fs.appendFileSync("./滕王阁序.txt","\r\n烟光凝而暮山紫") // fs模块中 \r\n表示换行
# 2.1.5 流式写入
程序打开一个文件是需要消耗资源的,流式写入可以减少文件的打开和关闭次数,因此流式写入适合大文件写入和频繁写入的场景;而writeFile( )适合的是写入频率较低的场景
//创建写入流对象
const ws = fs.createWriteStream("./早春呈水部张十八员外·txt")
//调用写入流对象的write()方法写入内容
ws.write("天街小雨润如酥\r\n");
ws.write("草色遥看近却无\r\n");
ws.write("最是一年春好处\r\n");
ws.write("绝胜烟柳满皇都\r\n");
//关闭流通道(可选)
ws.close()
# 2.2 文件读取
就是通过程序从文件中取出其中的数据, 场景:电脑开机、程序运行 、编辑器打开文件、 查看图片 、播放视频 、播放音乐 、 Git 查看日志( git log ) 、上传文件 、查看聊天记录 。
- readFile 异步读取
- readFileSync 同步读取
- createReadStream 流式读取
# 2.2.1 异步读取
语法: fs.readFile( path [, options], callback )
- path 文件路径
- options 选项配置
- callback 回调函数( null或错误信息,读取到的数据 )
//异步的读取文件
const fs = require("fs")
fs.readFile("./早春呈水部张十八员外·txt",(err,data)=>{
if(!err){
console.log(data); // 打印的是二进制Buffer
console.log(data.toString()); // 把Buffer转字符串,可以得到正确的诗词
return
}
console.log("读取失败");
})
# 2.2.2 同步读取
语法:fs.readFileSync( '文件路径' )
const fileBuffer = fs.readFileSync("./早春呈水部张十八员外·txt")
console.log(fileBuffer.toString());
# 2.2.3 流式读取
//创建流式读取对象
const rs = fs.createReadStream("./video/dancer.mp4")
//读取: chunk是大小为64kB的每一个块,读取视频的一个块执行一次回调函数
rs.on("data",chunk=>{
// console.log(chunk); //每一个块的Buffer
console.log(chunk.length) //65536byte ===>64kB
})
//读取结束
rs.on("end",()=>{
console.log("读取视频完成");
})
# 2.3 文件复制
在 Node.js 中可以使用 fs.copyFile( ) 实现文件的复制功能,也可以既复制文件又更改文件名字
const fs = require("fs")
const path = require("path")
const clonePath = path.resolve(__dirname,"../test/server.js")
const newPath = path.resolve(__dirname,"./video/newServer.js")
fs.copyFile(clonePath,newPath,err=>{
if(err)console.log(err)
else console.log("server.js文件复制并更改名字成功")
})
文件先读再写就可以完成一个复制功能
//方式一:使用常规的文件读取后再写入另一个文件
const fs = require("fs")
//读取
const readFiles = fs.readFileSync("./video/dancer.mp4")
//写入
fs.writeFileSync("./video/dancer-2.mp4",readFiles)
//方式二 : 使用流式读取和写入 (性能更好)
//创建读取流对象
const rs = fs.createReadStream("./video/dancer.mp4")
//创建写入流对象
const ws = fs.createWriteStream("./video/dancer-3.mp4")
rs.on("data",chunk=>{
//边读边写,将每一个分片写入文件
ws.write(chunk)
})
//读取完成时触发
rs.on("end",()=>{
console.log("文件复制成功,一份新的dancer视频文件复制到video文件夹下");
})
//方式三 : pipe ()
//在方式二中不必再去绑定读取流的data事件,直接调用 pipe方法也可以实现复制
rs.pipe(ws)
# 2.4 文件重命名与移动
在 Node.js 中,可以使用 rename 或 renameSync 来移动或重命名文件或文件夹
语法:
- fs.rename( oldPath, newPath, callback )
- fs.renameSync( oldPath, newPath )
参数说明:
- oldPath 文件当前的路径
- newPath 文件新的路径
- callback 操作后的回调
const fs = require("fs")
//重命名 路径不变,改文件名即可
fs.rename("./早春呈水部张十八员外·txt","./诗词.txt",err=>{
if(!err){
console.log("重命名成功");
return
}
console.log("重命名失败");
})
//移动,文件的名称不变,修改前面的路径(移动时,移动到不存在的文件夹会移动失败,例:poem)
fs.rename("./诗词.txt","./poem/诗词.txt",err=>{
if(!err){
console.log("移动成功");
return
}
console.log("移动失败");
})
# 2.5 文件删除
在 Node.js 中,我们可以使用 unlink 或 unlinkSync 或 rm 来删除文件
语法:
- fs.unlink( path, callback )
- fs.unlinkSync( path )
rm( ) 同上
fs.unlink("./诗词.txt",err=>{
if(!err){
console.log("删除成功");
return
}
console.log("删除失败");
})
//第二种方式
fs.rm("./诗词1.txt",err=>{
if(!err){
console.log("删除成功");
return
}
console.log("删除失败");
})
# 2.6 文件夹的创建/读取/删除
借助 Node.js 的能力,我们可以对文件夹进行 创建 、读取 、删除 等操作
- mkdir / mkdirSync 创建文件夹
- readdir / readdirSync 读取文件夹
- rmdir / rmdirSync 删除文件夹
语法:
- fs.mkdir( path [, options], callback )
- fs.mkdirSync( path [, options] )
# 2.6.1 创建文件夹
//创建单个文件夹
fs.mkdir("./utils",err=>{
if(!err){
console.log("创建成功");
return
}
console.log("创建失败");
})
//创建多层级文件夹,需要添加配置项
fs.mkdir("./audio/myAudio",{ recursive:true },err=>{
if(!err){
console.log("创建成功");
return
}
console.log("创建失败");
})
# 2.6.2 读取文件夹下的资源
//例: 读取当前js文件的父级文件夹下有哪些资源
fs.readdir("./",(err,data)=>{
if(!err){
console.log(data);// 数组 [ '1.js', 'audio', 'utils', 'video' ]
}
console.log("读取文件夹失败");
})
# 2.6.3 删除文件夹
在 Node.js 中,我们可以使用 rmdir 或 rm 来删除文件, 推荐使用 rm 方法
//删除单层级文件夹
fs.rmdir("./utils",err=>{
//提示
})
//删除多层级文件夹,需要添加 recursive配置项
fs.rmdir("./audio",{ recursive:true },err=>{
//提示
})
//删除文件夹建议使用rm()
fs.rm("./audio",{ recursive:true },err=>{
//提示
})
# 2.7 查看文件/文件夹的状态
在 Node.js 中,我们可以使用 stat 或 statSync 来查看资源的详细信息
语法:
- fs.stat( path [, options], callback )
- fs.statSync( path [, options] ) 参数说明:
- path 文件夹路径
- options 选项配置( 可选 )
- callback 操作后的回调
fs.stat("./video/dancer.mp4",(err,data)=>{
if(!err){
console.log(data); //资源的信息(资源的创建时间、修改时间、文件大小等)
//资源是不是文件
console.log(data.isFile()); // true
//资源是不是文件夹
console.log(data.isDirectory()); // false
return
}
console.log("查看资源状态失败");
})
# 三、Path模块
Node.js 中的模块提供了用于处理文件和目录的路径的实用工具。 先了解相对路径和绝对路径, 再去介绍 Path 模块提供的一些 API
# 相对路径
相对路径是指以当前文件资源所在的目录为参照基础,链接到目标文件资源(或文件夹)的路径。
//相对路径
fs.writeFileSync("./index.txt","hello")
fs.writeFileSync("index.txt","hello") //两种相对路径写法一样,都会在当前js文件同级目录新建index.txt文件
# 绝对路径
绝对路径就是文件的真正存在的路径,是指从硬盘的根目录(盘符)开始,进行一级级目录指向文件 ;
__filename : 可以大致理解为一个全局变量,表示当前js程序文件的绝对路径 ;
__dirname :可以大致理解为一个全局变量,表示当前js文件所在的文件目录的绝对路径(即,当前js文件的父级);
//绝对路径(例:在D盘根目录新建一个index.txt)
fs.writeFileSync("D:index.txt","hello")
fs.writeFileSync("C:index.txt","hello") //报错,权限不够
fs.writeFileSync(`${__dirname}/index.txt`,"hello world") //在当前js程序文件的同级目录新建了index.txt
console.log(__filename); // E:\study\node\test\index.js
console.log(__dirname); // E:\study\node\test
/* node.js 中的相对路径是按照终端所在的文件位置决定的,而不是当前js程序所在的位置决定的,这就导致在不同的
位置执行同一个js文件时,里面的相对路径都不相同(可以使用绝对路径__dirname解决这个问题) */
# path模块的一些API
- path.resolve 把全部给定的 path 片段按规则拼接到一起, 并规范化生成的绝对路径( 常用 )
- path.join 把全部给定的 path 片段按规则拼接到一起,并规范化生成的相对路径
- path.sep 获取操作系统的路径分隔符
- path.parse 解析路径并返回对象
- path.basename 获取路径的基础名称
- path.dirname 获取路径的目录名
- path.extname 获得路径的扩展名
# 1. path.resolve ( )
path.resolve( ) 用于拼接规范的路径,会把一个路径或路径片段的序列解析为一个绝对路径 ;
拼接规则: 想要理解path.resolve( )对路径片段的拼接规则,我们从三种情况中去入手 ;
情况一: path.resolve( )接收的所有路径片段中不带 / 或者为 ./ ===> 此时所有参数都会被拼接到当前目录的后面
const path = require("path")
console.log(__filename); // E:\study\node\test\index.js
console.log( path.resolve(__dirname) ); //E:\study\node\test 注:当前js程序文件所在的工作目录(js文件的父级)
// 注: 不带 /的情况
console.log( path.resolve("a") ); // E:\study\node\test\a 不加__dirname,自动找到了__dirname再去拼接a
console.log( path.resolve(__dirname,"a") ); // E:\study\node\test\a
console.log( path.resolve(__dirname,"a","b") ); // E:\study\node\test\a\b
// 注: ./的情况
console.log( path.resolve(__dirname,"./a") ); // E:\study\node\test\a
console.log( path.resolve(__dirname,"./a","./b") ); // E:\study\node\test\a\b
console.log( path.resolve(__dirname,"a","./b","c") ); // E:\study\node\test\a\b\c
情况二: path.resolve( )接收的所有路径片段带 ../ ===> 拼接的过程中碰到 ../会跳出当前文件夹( 往前跳一级 ),然后再拼接上 ../后的片段
const path = require("path")
console.log( path.resolve(__dirname) ); //E:\study\node\test 注:当前js程序文件所在的工作目录(js文件的父级)
console.log( path.resolve(__dirname,"../") ); // E:\study\node 往前跳了一级,跳出了test文件夹
console.log( path.resolve(__dirname,"../a") ); //E:\study\node\a 往前跳了一级,再去拼接a
console.log( path.resolve(__dirname,"../a","../b") ); //E:\study\node\b 跳出a文件夹再去拼接b
console.log( path.resolve(__dirname, 'static_files/png/', '../gif/image.gif') ); //E:\study\node\test\static_files\gif\image.gif 跳出png文件夹再去拼接gif/image.gif
情况三: path.resolve( )接收的所有路径片段带 / ===> 以最后一个出现的带 / 参数为起始位置,不接受当前路径前的任何参数,包括文件所在路径( 即,最后一个 带 / 的路径片段为起始位置,且从当前文件所在的磁盘开始拼接 )
const path = require("path")
console.log( path.resolve(__dirname) ); // E:\study\node\test 注:当前js程序文件所在的工作目录(js文件的父级)
console.log( path.resolve(__dirname,"/a") ); // E:\a 定向到E盘,再拼接a (最后一个带/的片段会定向到js文件所在的磁盘根目录,再去拼接)
console.log( path.resolve(__dirname,"/a","/b") ); // E:\b 定向到E盘,再拼接b
console.log( path.resolve(__dirname,"./a","/b","/c") ); // E:\c 定向到E盘,再拼接c (最后一个带/的路径片段作为起始位置,且它前面的所有路径片段都不可用)
console.log( path.resolve(__dirname,"/a/b","./c") ); // E:\a\b\c 定向到E盘,再拼接起始位置/a/b ,再拼接/c
console.log( path.resolve(__dirname,"./a","/b/c","../d") ); // E:\b\d 定向到E盘,再拼接起始位置/b/c ,然后跳出c再拼接d
读到这,我相信你是懂path.resolve( ) 的拼接规则的
# 2. path.join ( )
path.join( ) 会把全部给定的 path 片段连接到一起,并规范化生成的相对路径 ( 不会定向到磁盘根目录 )
拼接规则:
- 带/ 和 ./ 的非空片段都会依次拼接 ( 但是 / 在开头和末尾都会保留, ./ 仅在末尾会保留。 path.resolve()则不会保留开头和末尾的斜杠 )
- ../ 也会跳出文件夹,返回上一级 ( 但是会保留末尾的/, 这是与 resolve 不同的地方 )
- .. 跳出文件夹,返回上一级
- "" 空片段为空会跳过此片段
看几个例子就明白了...
console.log( path.join("b") ); // b
console.log( path.join("/b") ); // /b 保留开头\
console.log( path.join("./b") ); // b ./不会保留开头的\
console.log( path.join("a","b") ); // a\b 依次拼接
console.log( path.join("/a","/b/") ); // \a\b\ 依次拼接并保留末尾的\
console.log( path.join("/a","b","./") ); // \a\b\ 依次拼接并保留末尾的\
console.log( path.join("/a","./","./b") ); // \a\b 依次拼接( 第二片段已经到了a目录下,./返回a目录,再去拼接./b )
console.log( path.join("./a","/b","/") ); // a\b\ 依次拼接,不保留前面的./ , 保留后面的 /
console.log( path.join("./","./a","/b","/") ); // a\b\ 依次拼接,不保留前面的两个./ , 保留后面的 /
console.log( path.join("./a","/b","../c") ); // \a\c ../跳出了b目录,进入a目录再去拼接c
console.log( path.join("./a","/b","..") ); // a ..跳出了b目录,进入a目录
console.log( path.join("./a","/b","../") ); // a\ ..跳出了b目录,进入a目录,并保留了末尾的/
console.log( path.join("./a","","c") ); // a\c
console.log(__dirname); // E:\study\node\test
console.log( path.join( __dirname,"./a","/b","c","../d/" ) ); // E:\study\node\test\a\b\d\
读到这,我相信你是懂path.join( ) 的拼接规则的
# 3. path.extname ( )
console.log(__filename); // E:\study\node\test\index.js
const fileExt = path.extname( __filename )
console.log(fileExt); // .js
# 四、http模块
谈 Node.js 的 http 模块之前,先大致了解一下什么是 HTTP。HTTP(Hypertext transfer protocol)超文本传输协议,是互联网的一种通信协议,用于客户端与服务器之间的通信,它规定了客户端和服务器之间的通信格式,包括请求与响应的格式。它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。
Node.js 中的 http 模块是 Node.js 官方提供的、用来创建 web 服务器的模块,通过 http 模块提供的 http.createServer( ) 方法,就能方便的把一台普通的电脑,变成一台 Web 服务器,从而对外提供 Web 资源服务
# 4.1 创建HTTP服务
//引入http模块
const http = require("http")
//创建服务
const server = http.createServer((req,res)=>{
// 此回调函数会在浏览器客户端发起请求的时候调用,可以获取到请求相关的信息和设置要响应的内容
// res.end("hello world") //设置响应体
res.setHeader("content-type","text/html;charset=utf-8")
res.end("你好") //响应体中文乱码,可以通过上面设置响应头添加;charset=utf-8 utf-8编码解决
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
//注:HTTP协议的默认端口号是80,HTTPS协议的默认端口号是443
//浏览器访问 127.0.0.1:3000 即可; 如果使用了默认的80端口,访问127.0.0.1即可
# 4.2 获取请求头和请求参数相关信息
// 假设完整 url ===> http://127.0.0.1:3000/list-search?pages=1&rows=20
const http = require("http")
//引入 url 模块
const url = require("url")
//创建服务
const server = http.createServer((req,res)=>{
//一、获取请求行和请求头相关信息
console.log( req.httpVersion ); //获取http协议版本 ===> 1.1
console.log( req.url ); // 获取url中的接口路径和查询字符串部分 ===> /list-search?pages=1&rows=20
console.log( req.method ); // GET
console.log( req.headers ); // 获取请求头的信息 ===> 请求头信息对象
console.log( req.headers.host ); // 请求的服务器主机地址和端口 ===> 127.0.0.1:3000
//二、获取请求路径和请求参数相关信息 ( 借助Node.js 的 url 模块来序列化路径 )
let pathRes = url.parse(req.url,true)
//获取路径
let requestPath = pathRes.pathname
//获取参数对象
let requestQueryObj = pathRes.query
console.log( requestPath ); // /list-search
console.log( requestQueryObj ); // { pages: '1', rows: '20' }
//三、使用Node.js的URL类也可以获取请求的路径和请求参数等相关信息
const myUlr = new URL(req.url,"http:127.0.0.1") // 参数二 : 协议和域名/IP地址
//获取路径
console.log( myUlr.pathname );// /list-search
//获取请求参数
console.log( myUlr.searchParams.get("pages") ); // 1
res.end("hello world")
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
# 4.3 设置响应体相关信息
const http = require("http")
//创建服务
const server = http.createServer((req,res)=>{
//设置响应状态码
res.statusCode = 200
//设置响应状态描述
res.statusMessage = "okok"
//设置响应头( key,value )
res.setHeader("content-type","text/html;charset=utf-8")
//设置同名响应头
res.setHeader("myCustomServer",["NodeJs","JavaScript","abc"]) //设置了三个同名的 myCustomServer 请求头 ,值分别为 NodeJs 、JavaScript、abc
//设置响应体 ( write设置了响应体一般就不在end里再写了 ),服务端设置的响应体内容可以在浏览器Network的Response和Preview中查看
res.write("返回一个 hello world给浏览器客户端")
res.end()
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
响应练习 : 尝试给浏览器客户端响应一段 html 字符串(浏览器客户端会自动解析响应体中的 html 字符串,展示到页面上) 例:响应一段 html 字符串让浏览器解析为一个两行三列的 table 表格,第一行和第二行颜色不同,并且点击单元格可以 toggle 来回切换一个黑色背景色
const http = require("http")
//创建服务
const server = http.createServer((req,res)=>{
res.end(`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!-- 样式 -->
<style>
td{
padding:15px 35px;
}
table,td{
border-collapse:collapse;
}
table tr:nth-child(odd){
background-color:#40E0D0;
}
table tr:nth-child(even){
background-color:pink;
}
.toggleBlock{
background-color:#000;
}
</style>
</head>
<!-- 结构 -->
<body>
<table border="1">
<tr><td /><td /><td /></tr>
<tr><td /><td /><td /></tr>
<tr><td /><td /><td /></tr>
</table>
</body>
<script>
//脚本
let allTd = document.querySelectorAll("td")
allTd.forEach(item=>{
item.onclick = ()=>{
item.classList.toggle("toggleBlock")
}
})
</script>
</html>
`)
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
//浏览器地址栏访问127.0.0.1:3000就可以看到这个两行三列的table表格了
上面有一个明显的问题就是, html、css、js都是在无代码提示的情况下纯手写的, 显然很不方便, 这个时候我们可以借助 fs 文件系统模块对它做一些调整
const http = require("http")
const fs = require("fs")
const path = require("path")
//创建服务
const server = http.createServer((req,res)=>{
//现在一个.html文件里写好上面res.send中响应的内容,假设叫 table.html
//解析文件路径
const filepath = path.resolve(__dirname,"./table.html")
//读取html文件内容
const responseHtmlBuffer = fs.readFileSync(filepath)
//设置响应体( 读取的Buffer也可以不转字符串,res.send( )接受Buffer类型和字符串类型的参数
)
res.end(responseHtmlBuffer.toString())
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
//浏览器地址栏访问127.0.0.1:3000就可以看到这个两行三列的table表格了
# 4.4 搭建一个静态资源服务
- 假设 index.html 文件里的 css、js 或者图片都是通过src或者href属性在外部链入的,这个时候浏览器解析 index.html 时, 遇到这些外部链入的资源会去发送一个新的请求去 获取这些外链资源 , 这个时候服务的回调函数会再次调用, 就需要返回相应的 css 或 js 或图片等资源 , 而不是都返回 html ;我们可以通过请求路径去返回相应资源;
- 假设文件资源目录如下:与当前 server.js 程序同级的 pageResource 文件夹( 静态资源目录/网站根目录 )下,有 css、js、images文件夹和 index.html 文件;文件夹内存放了相应的资源, index.html 链入了这些文件文件夹内的资源
目录结构
project
│
└───pageResource
│ │____css
│ │ index.css
│ │ ....css
│ |
| |____js
| | index.js
│ │ ....js
| |
| |____images
| | 1.png
│ | ....jpg
| |
| |____index.html
|
|______server.js //服务
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!-- 采用绝对路径的形式链入,请求资源时服务的回调函数中可以获取到此路径,再去拼接资源根目录 -->
<link rel="stylesheet" type="text/css" href="/css/index.css" />
</head>
<body>
<h1>返回HTML</h1>
<img src="/images/1.png" alt="">
</body>
<!-- 相对路径也可以,但没有绝对路径可靠 -->
<script src="./js/index.js"></script>
</html>
服务server.js
//server.js
const http = require("http")
const fs = require("fs")
const path = require("path")
//创建服务
const server = http.createServer((req,res)=>{
//获取用户请求的路径
const {pathname} = new URL(req.url,"http:127.0.0.1") //解构赋值
// console.log( pathname); //如 /index.html 或 /css/index.css
//获取绝对资源路径
const filepath = __dirname + "/pageResource" + pathname // E:\study\node\test/pageResource/css/index.css
//读取文件内容
fs.readFile(filepath,(err,data)=>{
if(err){
res.statusCode = 500
res.end("error")
return
}
//响应资源
res.end(data)
})
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
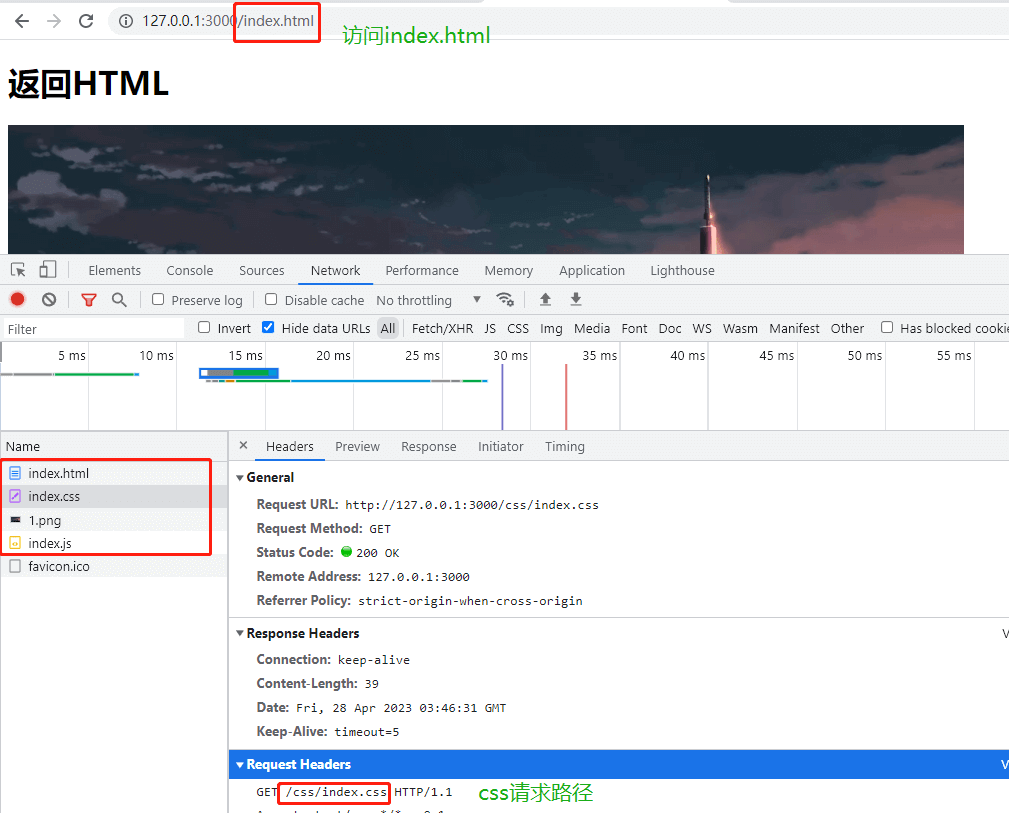
- 浏览器访问资源 127.0.0.1:3000/index.html, 发起网络请求, server.js 中的回调函数执行, 根据请求路径 /index.html 拼接的资源路径找到了相应的资源,并响应给浏览器, Network 中查看浏览器发送的几个请求中都正确返回了相应的html、css、js、图片,而不是都返回 html ;
- 单独访问127.0.0.1:3000/css/index.css 也可以正确返回相应的css资源
访问127.0.0.1:3000/index.html
# 4.5 网页URL中的绝对路径与相对路径
绝对路径
- https://www.baidu.com 完整地址形式, 直接指向了目标地址, 常用于网站外链
- //www.baidu.com/img/1.png 省略协议的形式, 会去自动拼接当前网页的协议形成完整路径,再去请求资源
- /static/img/1.png 会去自动拼接当前网页的协议、域名、端口形成完整路径再去请求资源 例:
<img src="/static/img/1.png" />
相对路径
相对路径在发送请求时,会与当前路径进行一定规则的重新拼接, 再去发送请求, 例:当前网页地址为 https://www.baidu.com/pages/index.html
- ./static/img/1.png ===> https://www.baidu.com/pages/static/img/1.png , ./ 会寻找到当前 index.html 的工作目录( 即, index.html 的父级文件夹 ), 再去拼接 /static/img/1.png
- ./static/img/1.png ====> 同上
- ../static/img/1.png ====> https://www.baidu.com/static/img/1.png , ../ 跳出了工作目录进入了根目录, 再去拼接 /static/img/1.png
# 4.6 响应错误信息给浏览器客户端
const http = require("http")
const fs = require("fs")
//创建服务
const server = http.createServer((req,res)=>{
//假设需要GET请求
if(req.method !== "GET"){
res.statusCode = 405
res.end('<h1> 405 Request Method Not Allowed <h1>')
return
}
const {pathname} = new URL(req.url,"http:127.0.0.1") //解构赋值
//获取绝对资源路径
const filepath = __dirname + "/pageResource" + pathname
fs.readFile(filepath,(err,data)=>{
if(err){
//判断错误码
switch(err.code){
case "EPERM":
res.statusCode = 403
res.end("<h1> 403 Forbidden </h1>")
break;
case "ENOENT":
res.statusCode = 404
res.end("<h1> 404 Not Found </h1>");
break;
default:
res.statusCode = 500
res.end("<h1> 500 Interval Server Error </h1>")
}
return
}
//正常
res.statusCode = 200
res.end(data)
})
})
//监听一个端口,启动服务
server.listen(3000,()=>{
console.log("服务启动成功");
})
# 五、模块化
在 Node.js 中, 应用由模块组成。 模块可以使用require 函数来引入其他模块,使用 module.exports 来导出模块中的数据或函数。模块化开发可以提高程序的可维护性、可扩展性和代码的复用性( 模块化开发使得程序中的代码可以被多次使用,不同的模块之间可以互相引用和调用,从而减少代码的重复编写 )。 毫无疑问, 在多人协作开发项目时, 模块化开发的思想变得尤为重要。
其实每个 js 文件就算一个模块, 每个模块都有一个独立的作用域, 在这个文件中定义的变量、函数、对象都是私有的, 对其他文件不可见。
语法 : module.exports 来导出模块 , require 函数来导入模块
使用 require 函数导入 Node.js 的内置模块时无需加./ 和 ../ , 导入 自定义的模块时,相对路径必须加上相应的./ 和 ../
如果导入的路径是个文件夹, 则会首先检测该文件夹下 package.json 文件中 main 属性对应的路径文件, 如果 main 属性对应路径文件存在则导入, 如果文件不存在会报错。
如果导入的路径是个文件夹, 且导入的文件夹下的 package.json 文件不存在或者 package.json 文件中 main 属性不存在, 则会尝试导入文件夹下的 index.js 和 index.json, 如果还是没找到, 就会报错
//myCustomModule.js
const list = [
{label:"商用",value:"0"},
{label:"非商用",value:"1"}
]
const sayHello = ()=>{
console.log("hello world")
}
//导出
module.exports = {
list, //ES6
sayHello
}
//index.js
//导入自定义模块
const customFun = require("./myCustomModule.js")
customFun.sayHello() // hello world
# 六、npm包管理工具
npm 全称 Node Package Manager , 翻译为中文意思是『Node 的包管理工具』, 是 Node.js 官方内置的包管理工具。Node.js 在安装时会自动安装 npm , 即下载安装了 Node.js 就已经可以使用 npm 了。
这里介绍一个能解决 Node.js 在使用 http 模块开发时, 每次更改代码都要重启服务的 npm 包 : nodemon , 安装这个包之后, 使用 npmmon 执行程序文件( 如 server.js ), 之后修改代码后保存会自动重启服务, 不用再去终端手动执行 node server.js 了 ( windows 执行 npmmon server.js 可能会报错, 使用管理员身份打开 PowerShell, 输入 set-ExecutionPolicy remoteSigned 回车 , 选择 "A全是" 即可)
npm 官网链接 : https://www.npmjs.com/
npm一些常用命令:
安装
- npm -v 查看 npm 的版本
- npm init 初始化 package.json 文件, npm init -y 会跳过提问, 直接初始化 package.json 文件
- npm install / npm i 根据package.json 安装项目所需的依赖包
- npm install packageName 安装某个模块 (模块记录在 package.json 的 dependencies 中)
- npm install packageName --save / npm install packageName -S 安装某个模块 (模块记录在 package.json 的 dependencies 中)
- npm install webpack --save-dev / npm install webpack -D 安装某个模块 (模块记录在 package.json 的 devDependencies 中, 开发环境依赖包)
- npm install packageName -g 全局安装模块
- npm install packageName@3.10.0 使用@符号安装指定版本
卸载
- npm uninstall packageName 卸载模块
- npm uninstall packageName -g 卸载全局模块
更新
- npm update packageName --save-dev 更新某个指定的模块
- npm update packageName -g 更新某个指定的全局模块
设置 npm 淘宝镜像
- npm install -g cnpm --registry=https://registry.npmmirror.com
接下来尝试在项目中使用一个 npm 包...
//项目根目录初始化 package.json 文件
npm init -y
//安装 一个去重的包 uniq
npm install uniq // 会生成node_modules 文件夹,并将uniq包加入其中;还会生成packages-lock.json锁定uniq包的版本; 包名会添加到 package.json 文件的 dependencies 中
//引入 node_modules中的 uniq
const uniq = require("uniq")
//使用
const uniqList = uniq([1,1,2,2,3,4,5,5])
console.log(uniqList) // [1,2,3,4,5]